Plik robots.txt - zastosowanie i przykłady
Jednym z pierwszych elementów technicznej optymalizacji strony internetowej jest analiza pliku robots.txt. Z tego wpisu dowiesz się, dlaczego należy zadbać o jego prawidłową budowę i dlaczego tylko część botów respektuje dyrektywy w nim zawarte. Znajdziesz też kilka przykładów, które pomogą Ci zrozumieć strukturę pliku robots.txt.
- Autor:
- Daniel Jędrysik
- Czas czytania:
- Publikacja:
- 28 września 2020
- Aktualizacja:
- 31 marca 2022
- Kategorie:
Jednym ze sposobów, który umożliwia nam blokowanie swobodnego przemieszczania się robotom po naszej stronie jest plik robots.txt. Z tego wpisu dowiesz się co to jest plik robots.txt, do czego się go wykorzystuje, jakie reguły zawiera oraz dlaczego warto poświęcić czas na jego prawidłowe przygotowanie.
Z tego artykułu dowiesz się:
- Co to jest plik robots.txt?
- Jaką funkcję pełni plik robots.txt?
- Gdzie znajduje się plik robots.txt?
- Jak zbudowany jest plik robots.txt?
- Przykłady pliku robots.txt
- Czy każdy robot przestrzega dyrektyw zawartych w pliku?
- Narzędzia do testowania blokowania zasobów przez plik robots.txt
- Dlaczego nie należy ignorować pliku robots.txt?
Co to jest plik robots.txt?
Plik robots.txt to plik tekstowy, który zawiera dyrektywy mające na celu wskazanie robotom przeczesując Internet, które zasoby (strony, zdjęcia, skrypty) mogą zostać przeskanowane. Stosuje się go w celu ograniczenia nadmiernego obciążania serwera, a nie – jak błędnie niekiedy jest przyjmowane – do ukrywania stron przed robotami.
Robots.txt jest jednym z mechanizmów Robot Exclusion Protocol – czyli protokołu informującego roboty o tym, czego nie powinny robić w obrębie stron internetowych.

Dla zainteresowanych: Drugim mechanizmem są znaczniki meta umieszczane w sekcji <head> strony internetowej.
Robot Exclusion Protocol (REP) został wprowadzony w 1994 roku i szybko stał się standardem przestrzeganym przez crawlery sieciowe. Twórcą podwalin pod REP jest Martijn Koster, który to doświadczył wzmożonego ruchu crawlerów na swoje stronie.
1 lipca 2019 roku Google ogłosiło, że wraz z twórcą protokołu, deweloperami z całego świata oraz innymi twórcami crawlerów postanowili sformalizować sposób wykorzystania REP w nowoczesnej sieci i złożyli dokumentację do Internet Engineering Task Force. Projekt w chwili obecnej poddawany jest ocenie.
Jaką funkcję pełni plik robots.txt?
Plik robots.txt służy głównie do zarządzania ruchem robotów w obrębie całej witryny lub tylko jej części. Używany jest również do blokowania indeksowania strony przez roboty indeksujące. O ile w pierwszym przypadku robots.txt sprawdza się bez zarzutu to już przy indeksowaniu stron mogą wystąpić pewne problemy. Jak już wspomniałem wcześniej używanie pliku do zapobiegania wyświetlania strony w wynikach wyszukiwania bywa nieskuteczne. Jeżeli do zablokowanej strony prowadzić będą odnośniki opisowe, algorytm może uznać, że strona warta jest wyświetlenia w SERPach. W takim przypadku mimo, że robot nie był na stronie i nie pobrał jej zawartości, może ona pojawić się w wynikach wyszukiwarki Google.
Trochę inaczej sprawa ma się z plikami multimedialnymi, skryptami i plikami styli. Umieszczenie dyrektywy disallow nie tylko uniemożliwia pobranie i przeskanowanie tych zasobów przez robota, ale także zapobiega ich indeksowaniu.
Gdzie znajduje się plik robots.txt?
Plik robots.txt jest pierwszym plikiem, który pobierany jest przez roboty skanujące stronę. Dlatego też powinien on znajdować się w katalogu głównym domeny. Jeżeli go tam nie ma, wszystkie roboty indeksujące mogą bez przeszkód skanować zawartość Twojej strony.
Aby sprawdzić czy nasza witryna posiada plik robots.txt, w pasku przeglądarki wpisujemy adres URL naszej domeny dopisując na końcu /robots.txt. W przypadku mojej witryny będzie to wyglądało tak:
https://daniel-jedrysik.pl/robots.txt
Jeżeli naszym oczom ukaże się strona błędu 404 (o ile serwer jest poprawnie skonfigurowany) znaczy to, że pliku robots.txt nie posiadamy.
Jak zbudowany jest plik robots.txt?
Robots.txt jest plikiem tekstowym, więc do jego stworzenia lub edycji wystarczy prosty edytor tekstowy (np. windowsowy Notatnik, Atom, Notepad++). Plik powinien być zakodowany w UTF-8. Oznacza to, że jeżeli pojawią się w nim znaki spoza UTF-8 może dojść do błędnej analizy pliku.
Informacje dla robotów w pliku robots.txt zawarte są w grupach, przy czym powinna istnieć przynajmniej jedna grupa. Każda grupa składa się z reguł i dyrektyw zawierających informacje:
- jakiego klienta użytkownika dotyczy dana grupa,
- do jakich zasobów klient ma dostęp,
- do jakich zasobów klient nie ma dostępu.
Pierwszą dyrektywą w grupie jest zawsze dyrektywa informująca, kogo ona dotyczy. Wygląda ona tak:
user-agent: [user-agent-name]
Dla przykładu dyrektywa przypisująca grupę do konkretnego robota wyszukiwarki wygląda tak:
user-agent: Googlebot
lub
user-agent: Bingbot
Do najpopularniejszych klientów użytkownika należą:
- Googlebot
- Bing
- Slurp
- DuckDuckBot
- YandexBot
- Sogou Spider
- Exabot
- Alexa crawler
Po dyrektywie user-agent: następują dyrekrytywy wykluczające lub zezwalające na skanowanie konkretnych zasobów. Wyłączenie zasobu z crawlowania realizowane jest dyrektywą disallow. Z kolei dyrektywa allow umożliwia dostęp robotom indeksującym do katalogu lub pliku.
Po wszystkich grupach wskazane jest umieszczenie linku do mapy strony stosując dyrektywę sitemap.
W użyciu jest jeszcze jedna dyrektywa – crawl-delay – która ogranicza częstotliwość skanowania witryny przez roboty. Używa się ją przeważnie w sytuacjach, gdy zachodzi obawa, że w wyniku działalności robota, serwer nie wytrzyma obciążenia i przestanie odpowiadać. Google ignoruje tę dyrektywę – jest w stanie sam określić częstotliwość, z jaką strona będzie crawlowana. Z kolei Baidu, Yahoo, Yandex i Bing przestrzegają zapisów z pliku. W ich przypadku zapis crawl-delay: 10 informuje roboty o tym, by następną podstronę przeskanowały dopiero po upływie 10 sekund.
Przykłady pliku robots.txt
Oto kilka przykładów użycia pliku robots.txt do kontrolowania crawlerów odwiedzających nasza witrynę.
Przykład 1. Blokowanie dostępu do witryny
User-agent: *
Disallow: /
W powyższym przykładzie, każdy robot, respektujący zawarte w pliku dyrektywy, nie będzie w stanie pobrać zawartości witryny. Stosuje się go np. w przypadku stron w trakcie tworzenia. Należy jednak zaznaczyć, że taki zapis w pliku robots.txt nie gwarantuje, że URL nie zostanie zaindeksowany.
Przykład 2. Zablokowanie konkretnego robota przed pobieraniem zawartości strony
User-agent: Bingbot
Disallow: /
User-agent: *
Allow: /
Plik robots.txt blokuje dostęp wyszukiwarce Bing do strony. Inne roboty mogą bez przeszkód pobierać zasoby naszej strony internetowej.
Przykład 3. Blokowanie robotom dostępu do wybranego katalogu
User-agent: *
Disallow: /obrazy/
Wszystkie pliki umieszczone w katalogu obrazy są niedostępne dla robotów.
Przykład 4. Blokowanie konkretnego pliku i strony
User-agent: *
Disallow: /obrazy/zdjecie.jpg
Disallow: /katalog/oferta-prywatna/$
Podany przykład uniemożliwia pobranie pliku zdjecie.jpg oraz strony internetowej o adresie …/katalog/oferta-prywatna/.
W dyrektywie użyto znaku $, który oznacza koniec adresu URL. Oznacza to, że zablokowany jest tylko jeden adres i strony takie jak /katalog/oferta-prywatna/oferta-1/ będą mogły zostać zaindeksowane.
Przykład 5. Blokowanie adresów mających wspólną końcówkę
User-agent: Googlebot
Disallow: /*/feed/$
User-agent: *
Disallow: /*.pdf$
Pierwsza grupa dotyczy jedynie Googlebota i oznacza, że każdy adres kończący się na /feed/ będzie zablokowany dla tego klienta użytkownika.
Druga grupa dotyczy każdego klienta użytkownika i oznacza blokadę wszystkich plików pdf, niezależnie od tego, w jakim katalogu się znajdują. Dyrektywa wykorzystuje znak * oznaczający zero lub więcej wystąpień dowolnego prawidłowego znaku.
Przykład 6. Rozbudowany przykład pliku robots.txt uwzględniający wszystkie dyrektywy
User-agent: Googlebot
Allow: /obrazy/psy/
Disallow: /*.pdf$
User-agent: *
Disallow: /obrazy/
Crawl-delay: 10
Sitemap: http://www.example.com/ sitemap.xml
Rozłóżmy ten plik na składowe. Pierwsza grupa dotyczy jedynie Googlebota i zabrania dostępu do plików z rozszerzeniem pdf oraz odblokowuje dostęp do obrazów w katalogu /obrazy/psy/. Druga grupa dotyczy każdego robota i zabrania dostępu do katalogu /obrazy/ – choć Googlebot jest częściowo z tego wyłączony ponieważ w pierwszej grupie przyznaliśmy mu dostęp do jednego z katalogów w obrębie katalogu /obrazy/. Grupa zawiera również dyrektywę crawl-delay ograniczającą aktywność botów.
Ostatnią dyrektywą jest wskazanie robotom, gdzie mają szukać mapy strony. Nie zawsze jest to oczywiste miejsce, takie jak sitemap.xml, i mała podpowiedź ułatwi pracę crawlerom.
Czy każdy robot przestrzega dyrektyw zawartych w pliku?
Nie wszystkie roboty przestrzegają dyrektyw zawartych w pliku robots.txt. Dotyczy do głównie botów mających za zadanie kradzież danych, włamanie się na słabo zabezpieczone konto, przesyłać spamu za pomocą formularzy czy też w taki czy inny sposób zaszkodzenie użytkownikowi i/lub właścicielowi strony. Przed nimi nie uchroni nas plik robots.txt. Dlatego też powinniśmy zadbać o bezpieczeństwo naszej strony, a pliki prywatne zabezpieczać hasłem.
Narzędzia do testowania blokowania zasobów przez plik robots.txt
Plik robots.txt możesz przetestować wieloma narzędziami online, a dokładniej to, czy nie blokuje on ważnych dla nas zasobów.
Tester pliku robots.txt od Google
Jeżeli korzystasz z Google Search Console (a nie mogę wyobrazić sobie, żeby tak nie było – jeżeli nadal nie masz skonfigurowanej tej usługi koniecznie przeczytaj mój wcześniejszy artykuł: Weryfikacja usługi w Google Search Console – Krok po kroku) możesz skorzystać z wbudowanego narzędzia do testowania pliku robots.txt. Niestety wraz z pojawieniem się nowej wersji GSC dostęp do narzędzia nieco się skomplikował. Aby do niego dotrzeć musimy troszkę się napocić.

W GSC klikamy po lewej stronie na Starsze narzędzia i raporty. Następnie w link Dowiedz się więcej. W okienku pomocy wpisujemy robots.txt i wchodzimy na odnośnik Sprawdzanie pliku robots.txt za pomocą testera.

Zaraz pod informacja o narzędziu znajduje się przycisk Otwórz tester pliku robots.txt. Po klinięciu w niego zostaniemy przeniesieni na nową podstronę. Wybieramy interesującą nas domenę i już po chwili widzimy zawartość pliku, do którego ma dostęp Google. Dla niecierpliwych podaję bespośredni link do narzędzia: https://www.google.com/ webmasters/ tools/ robots-testing-tool

Jeżeli chcemy sprawdzić, czy strona lub zasób nie jest przypadkiem niedostępny dla botów Google wystarczy wprowadzić adres URL (w postaci względnej czyli bez domeny), wybrać interesującego nas bota i wcisnąć przycisk TEST. Brak ograniczeń, co do skanowania pliku, zasygnalizowany zostanie zmianą koloru na zielony i napisu na przycisku (TEST zmieni się na ALLOW). Dla blokowanych zasobów, napis na przycisku będzie brzmiał BLOCKED i zostanie na czerwono podświetlona odpowiednia dyrektywa.
Zaletą korzystania z tego narzędzia jest fakt, że mamy możliwość sprawdzenia, czy przypadkiem nie blokujemy dla Googlebota jakichś istotnych plików. Wadą jest to, że przetestujemy jedynie boty ze stajni Google.
robots.txt Validator and Testing Tool
Innym ciekawym narzędziem, z którego korzystam regularnie jest robots.txt Validatior and Testing Tool – dostępne jest pod tym adresem: https://technicalseo.com/tools/robots-txt/. Mamy w nim możliwość sprawdzenia dostępności plików dla większości robotów. Zasada działania jest podobna jak w przypadku narzędzia od Google. Dyrektywa blokująca podany adres URL podświetlana jest na czerwono. W przypadku braku przeciwwskazań, na zielono zostaje oznaczona odpowiednia dyrektywa oraz na dole strony pojawia się informacja Result: Allowed.
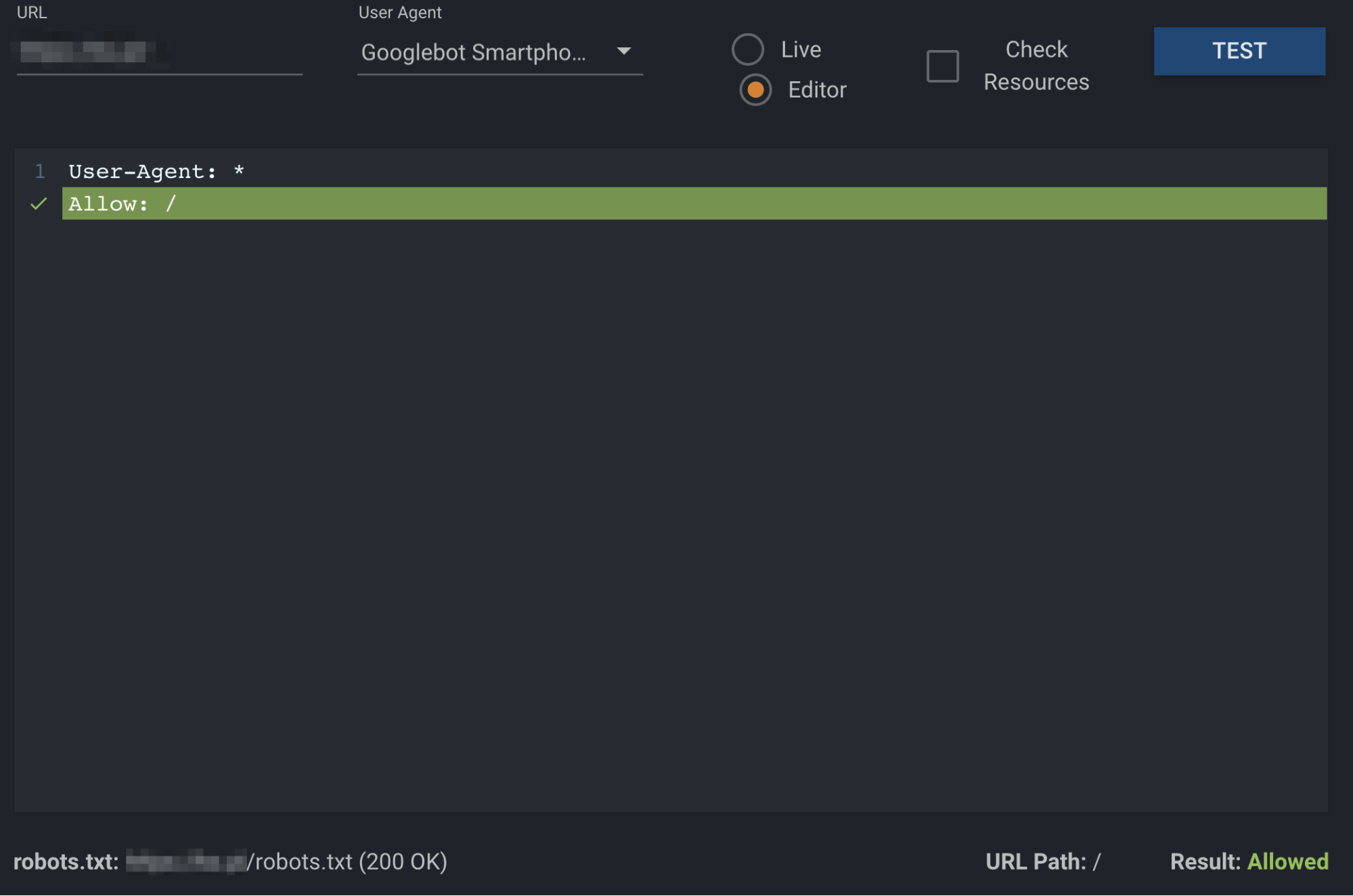
Oba przytoczone narzędzia pozwalają na edycję i testowanie własnych dyrektyw, które następnie możemy wdrożyć do pliku robots.txt.
Dlaczego nie należy ignorować pliku robots.txt?
Można zadać pytanie – skoro plik robots.txt, z jego regułami i dyrektywami, może powodować problemy z indeksacją naszej strony, to czy musimy go posiadać? Moim zdaniem warto. Zbyt szeroki dostęp robotów do strony WWW sprawia, że zamiast indeksować wartościowe treści, na których nam zależy, skanują bezwartościowe zasoby. W przypadku innych wyszukiwarek niż Google mamy też możliwość ograniczenia częstotliwości skanowania zasobów, co zapobiegnie nadmiernemu obciążaniu serwera. Dlatego też jednym z pierwszych działań SEO, jakie podejmuję przy optymalizacji technicznej strony jest analiza pliku robots.txt. Wam też polecam przyjrzeć się bliżej temu plikowi.
Jeśli będziecie mieli pytania związane z tym wpisem, zapraszam do kontaktu na moim profilu na LinkedIn lub na Facebooku.

Od 2018 roku związany jestem z marketingiem internetowym. Specjalizuję się w optymalizacji stron internetowych i sklepów. Obecnie pełnię funkcję Marketing Managera w Agencji KS. Prywatnie jestem miłośnikiem fantastyki oraz zapalonym czytelnikiem.