Indeksowanie strony w Google, czyli jak dodać stronę do wyszukiwarki Google
Najlepsze treści i zachwycające grafiki nie pomogą, jeżeli użytkownicy nie będą w stanie znaleźć Twojej strony. Dowiedz się co oznacza termin indeksacja oraz sprawdź czy nie blokujesz tego procesu na swojej stronie. We wpisie przeczytasz także o 4 sposobach na dodanie strony do wyszukiwarki Google.
- Autor:
- Daniel Jędrysik
- Czas czytania:
- Publikacja:
- 17 maja 2020
- Aktualizacja:
- 10 kwietnia 2022
- Kategorie:
Ruch na naszej stronie możemy generować na wiele sposobów. Poprzez udostępnianie artykułów na portalach społecznościowych, umieszczanie odnośników (linków) do strony w sieci czy też tworzenie treści, które Google będzie skłonne wyświetlać wysoko na popularne zapytania. Dla znacznej ilości młodych, rozwijających się blogów głównym źródłem ruchu będą portale społecznościowe i osoby, które odwiedzają strony wchodząc na nie bezpośrednio podając adres URL. Jednak na dłuższą metę to wyniki organiczne powinny być głównym źródłem ruchu dla witryny. Ale żeby tak się stało strona najpierw musi trafić do indeksu Google.
W tym wpisie dowiecie się m.in. dlaczego strona powinna znajdować się w indeksie Google, jakie czynniki blokują roboty przed indeksowaniem treści oraz jak dodać stronę do Google.
Z tego artykułu dowiesz się:
- Dlaczego indeksowanie strony jest tak istotne
- Kiedy strona może zostać dodana do indeksu Google
- Plik robots.txt
- Meta robots
- Nagłówek HTTP X-Robots-Tag
- Adres kanoniczny
- Jak dodać stronę do Google
- Poczekaj, aż Google sam odkryje nową stronę
- Indeksowanie strony w Google Search Console
- Dodaj stronę do mapy witryny
- Umieść link do strony w miejscu często odwiedzanym przez roboty
- Skorzystaj z Google Indexing API
- Jak długo trzeba czekać na zaindeksowanie strony?
- Jak sprawdzić czy strona została zaindeksowana?
- Dlaczego moja strona nie została zaindeksowana?
- Na zakończenie
Dlaczego indeksowanie strony jest tak istotne?
Tutaj możemy posłużyć się prostą analogią. Indeks Google czy innych wyszukiwarek możemy porównać do katalogu, który prowadzi każda biblioteka. Z jego pomocą jesteśmy w stanie bez problemu określić czy dana publikacja znajduje się w księgozbiorze oraz w jakim miejscu należy jej szukać.
Gdyby bibliotekarz zapomniałby umieścić książki w rejestrze, osoba przeglądająca katalog nie byłaby w stanie stwierdzić czy dana pozycja znajduje się w bibliotece czy nie. Na taką książkę trafiłaby jedynie przypadkowo przechadzając się między regałami.
Podobnie jest ze stronami internetowymi. Jeżeli robot nie umieści witryny w indeksie, nie będziemy w stanie do niej dotrzeć poprzez wyszukiwarkę.
Zgodnie z definicją umieszczoną na stronie wikipedia.org:
Katalog biblioteczny jest to uporządkowany rejestr dokumentów ułatwiający ich odszukanie, poprzez podanie ich cech indywidualnych, bibliograficznych oraz miejsca ich przechowywania.
Podobną definicję możemy podać dla indeksu Google:
Indeks wyszukiwarki Google jest to uporządkowany według ustalonych kryteriów zbiór stron internetowych, plików graficznych czy innego rodzaju plików, których odszukanie możliwe jest poprzez podanie cech indywidualnych (zapytanie) lub miejsca ich przechowywania (zapytanie w połączeniu z domeną, w obrębie której ma być przeprowadzone wyszukiwanie).
Kiedy strona może zostać dodana do indeksu Google
Dodanie strony do Google będzie możliwe jeżeli:
- w pliku robots.txt nie będzie dyrektywy blokującej dostęp robotowi do danego zasobu
- dokument html nie będzie posiadał znacznika
meta name="robots" content="noindex" - dla strony nie zostanie podany inny adres kanoniczny
- w nagłówku HTTP w odpowiedzi na żądanie nie pojawi się element X-Robots-Tag: noindex
Plik robots.txt
Plik ten umieszczony zazwyczaj w głównym katalogu, zawiera dyrektywy dla robotów przeczesujących sieć. Jeżeli umieścimy w nim komendę blokującą dostęp do naszej witryny, robot Google nie będzie w stanie przeskanować strony, co uniemożliwi jej dalsze przetworzenie. Innymi słowy nasza strona nie będzie miała szans na znalezienie się w wynikach wyszukiwania.
Dyrektywa uniemożliwiająca dostęp robotom do strony wygląda w ten sposób:
Disallow: /moja-strona/
Jak sprawdzić?
Aby stwierdzić czy nasz adres URL nie jest blokowany możemy sprawdzić czy w pliku robots.txt nie ma reguł ograniczających dostępność do witryny lub niektórych jej katalogów.
Ja osobiście korzystam z dwóch narzędzi:
Można również wykorzystać program ScreamingFrog, dzięki któremu przeanalizujecie od razu całą witrynę lub URL Inspection Tool w Google Search Console do analizy pojedynczego adresu.
Więcej o pliku robots.txt dowiesz się z wpisu: Plik robots.txt – zastosowanie i przykłady
Meta robots
Znaczniki meta , niewidoczne dla użytkownika, zawierają istotne informacje dla robotów. Jednym z takich znaczników jest meta name="robots". W atrybucie content możemy podać m.in informację o tym czy strona powinna być indeksowana czy nie. Jeżeli robot napotka w sekcji head linijkę meta name="robots" content="noindex" podstrona nie zostanie zaindeksowa.
Warto tutaj zaznaczyć, że wartość parametru name="robots" wskazuje, że dyrektywa odnosi się do wszystkich robotów. Jeżeli chcemy mieć pewność, że robot Google ma dostęp do naszej podstrony sprawdźmy także czy w kodzie strony nie występuje metatag o parametrach name="Googlebot" content="noindex".
Jak sprawdzić?
Także w tym przypadku niezwykle pomocna okazuje się „krzycząc żaba”. W raporcie ze skanowania witryny dostaniemy informacje o tym, czy dana strona nie zawiera metatagów uniemożliwiających indeksowanie.
Można również sprawdzić to „ręcznie”. Należy uruchomić DevTools w przeglądarce Chrome i wyszukać znaczniki meta lub użyć URL Inspection Tool (Narzędzie do sprawdzania URL).
Nagłówek HTTP X-Robots-Tag
Jeżeli w odpowiedzi na żądanie klienta użytkownika w nagłówku HTTP zostanie przesłany element X-Robots-Tag: noindex strona nie zostanie zaindeksowana. Należy tutaj nadmienić, że, jak w przypadku metatagów, możemy określić jakich klientów będzie dotyczyła nasza dyrektywa. W przypadku, gdy nie podamy w dyrektywie klienta, domyślnie dotyczyć ona będzie każdego robota.
Jak sprawdzić?
Dla pojedynczej strony można z powodzeniem wykorzystać narzędzie dostępne pod adresem: http://www.redirect-checker.org/. Poza kodem odpowiedzi strony czy wskazaniem łańcucha przekierowań, zwraca ono odpowiedzi w nagłówku HTTP.
Dodatkową zaletą jest także to, że możemy wybrać klienta użytkownika, którego chcemy użyć do testów.
Także wbudowane w Google Search Console narzędzie do analizy URLi poda czy dany adres nie zawiera dyrektyw blokujących indeksowanie strony w nagłówku HTTP.
Do analizy wielu adresów URL pod tym kątem polecam użycie narzędzia Screaming Frog.
Adres kanoniczny
Dzięki adresom kanonicznym możemy wskazać, która strona spośród wielu podobnych jest tą, która zasługuje na pojawienie się w wynikach wyszukiwania. Nie jest to dyrektywa wiążąca, gdyż algorytm czasem sam wybiera inny adres kanoniczny niż ten zaproponowany w tagu link rel="canonical". Jeżeli na analizowanej stronie pojawi się tag link rel="canonical" z innym adresem URL, istnieje ryzyko, że strona nie zostanie zaindeksowana.
Jak sprawdzić?
Najprostszym rozwiązaniem będzie sprawdzenie kodu źródłowego strony lub wykorzystanie jednego z przydatnych rozszerzeń do przeglądarek. Można również przeskanować witrynę Screaming Frog i wyłapać adresy, które mają ustawiony nieprawidłowy adres kanoniczny.
Jak dodać stronę do Google
Sposobów na indeksowanie strony w Google jest kilka. Różnią się szybkością dodania adresów URL do indeksu oraz poziomem skomplikowania. Zacznijmy więc od sposobów najprostszych.
Poczekaj, aż Google sam odkryje nową stronę
Metoda ta nie wymaga od nas żadnej interwencji, a jedynie cierpliwości. Robot codziennie przeczesuje odmęty Internetu w poszukiwaniu nowych treści i jeżeli będziemy mieli szczęście nowa podstrona zostanie przeskanowana i dodana do indeksu stosunkowo szybko. W przypadku nowych lub mało popularnych witryn może to potrwać od kilku do nawet kilkunastu dni. Jeżeli zależy nam na czasie możemy przyspieszyć indeksowanie przedstawionymi niżej sposobami.
Indeksowanie strony w Google Search Console
W Google Search Console (GSC) wbudowane zostało narzędzie do sprawdzania adresów URL należących do zweryfikowanej domeny lub usługi. Z jego pomocą możemy:
- sprawdzić, czy adres znajduje się w indeksie,
- zobaczyć czy nie występują z nim jakieś problemy (np, blokowanie robotów indeksujących, błędy w danych strukturalnych),
- zobaczyć jak Google renderuję stronę,
- a co najważniejsze zgłosić adres URL do dodania do indeksu Google.
Dlatego też, jeżeli jeszcze nie zweryfikowałeś swojej witryny, zrób to jak najszybciej. Z jednego z moich poprzednich wpisów dowiesz się, jak przebiega weryfikacja domeny lub strony w Google Search Console.
Jak to zrobić?
W górnym pasku narzędzie GSC znajduje się pole do wprowadzania adresów URL z tekstem: Sprawdź dowolny URL w „nazwa usługi”. Wystarczy, że w ten pasek wkleimy lub wpiszemy adres nowej strony, którą chcemy zaindeksować i klikniemy Enter. W ciągu kilku sekund zostaną pobrane informacje o podanym URL. Jeżeli nie będzie on znajdował się w indeksie, zobaczymy na ekranie szarą ikonę wraz z informacją.
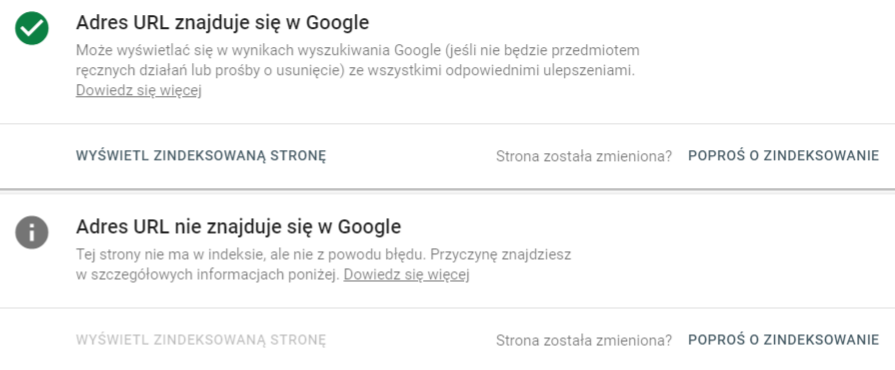
Klikając w przycisk Poproś o zaindeksowanie wysyłamy informację do Google o pojawieniu się nowej strony w Internecie, którą robot powinien odwiedzić, zeskanować i ostatecznie zaindeksować. Proces indeksowania może trwać od kilku minut do nawet kilku dni.
Dodaj stronę do mapy witryny
Kolejnym prostym sposobem na indeksowanie nowych podstron jest dodanie ich do mapy witryny. Mapa witryny – znana też jako plik sitemap.xml – to plik zawierający adresy URL, które uważamy za ważne. O samym pliku można by napisać osobny artykuł, dlatego też tutaj jedynie wspomnę, że Google wykorzystuje go do odkrywania nowych stron. Dodanie adresu URL nie spowoduje jednak, że szybko znajdzie się on w indeksie. Tutaj też musimy wykazać się cierpliwością. Aby przyspieszyć indeksowanie możemy dodać ponownie mapę strony do GSC. Dzięki temu robot szybciej dowie się o adresie i przeskanuje go w najbliższym możliwym dla niego czasie.
Jak to zrobić?
Systemy zarządzania treścią umożliwiają automatyczne dodawanie nowych adresów do mapy witryny. W przypadku systemu WordPress konieczna będzie instalacja jednej z wtyczek. Nie mniej jednak jest to proces na tyle prosty, że każdy powinien sobie z nim poradzić.
W pozostałych przypadkach pozostaje nam ręczne umieszczenie strony w mapie witryny lub skorzystanie z jednego z generatorów pliku sitemap.
Umieść link do strony w miejscu często odwiedzanym przez roboty
Wartym rozważenia sposobem jest umieszczenie linku do nowej podstrony w miejscu, które robot często odwiedza. W obrębie naszej domeny będzie to strona główna. Można także spróbować podlinkować stronę z zewnętrznych witryn.
Skorzystaj z Google Indexing API
Opcja dla zaawansowanych. Jeżeli choć trochę jesteś zaznajomiony z programowaniem w JavaScript lub Python to polecam dodanie strony do Google przez specjalnie do tego stworzone API. Google Indexing API umożliwia nie tylko zgłoszenie nowych adresów URL do indeksacji ale także aktualizację obecnych oraz usunięcie tych nieaktualnych. Dużą zaletą wykorzystania API jest możliwość wysłania do 200 żądań dziennie, czyli zgłoszenie do indeksu nawet 200 stron dziennie.
Jak długo trzeba czekać na zaindeksowanie strony?
Samo indeksowanie strony nie jest procesem długim. Google stara się ograniczyć czas na analizę jednej podstrony do minimum. W końcu ma do przeskanowania cały Internet, który nieustannie się rozrasta. Co innego jeżeli chodzi o odwiedzenie strony przez robota. Jeżeli nie poinformujemy go o nowej lub zaktualizowanej treści, jego wizyta może odbyć się nawet po kilku lub kilkunastu dniach.
W większości przypadków, korzystając z narzędzia do sprawdzania adresu URL, wasza strona pojawi się w wynikach wyszukiwania w przeciągu kilku, kilkunastu minut. Zdarzają się także przypadki zatory lub problemy z działaniem algorytmu. Wtedy indeksowanie może przeciągnąć się w czasie nawet do kilkunastu dni. Dla stron opartych w głównej mierze o JavaScript dochodzi jeszcze czas związany z wyrenderowaniem treści, co znacząco wydłuża cały proces indeksowania strony.

Jeżeli uważasz, że czas oczekiwania na zaindeksowanie strony jest stanowczo za długi, sprawdź czy nie zostały ustawione dyrektywy blokujące indeksowanie.
Jak sprawdzić czy strona została zaindeksowana?
Aby sprawdzić, czy strona została dodana do indeksu możemy wykorzystać dwie metody. Albo posłużyć się operatorem wyszukiwania site: albo użyjesz narzędzia do sprawdzania URL w Google Search Console.
Jeżeli po wpisaniu w pasku adresu przeglądarki parametru site: z adresem URL strony pojawi się poniższy komunikat, oznacza to, że nie została jeszcze zaindeksowana.

Nie jest to metoda w 100% pewna, jednak daje ogólny pogląd czy robot odwiedził i dodał stronę do wyników wyszukiwania.
Druga metoda polega na sprawdzeniu w GSC czy Google ma w indeksie informacje o podanym adresie URL. Używamy do tego oczywiście wbudowanego narzędzia do sprawdzania URL.
Dlaczego moja strona nie została zaindeksowana?
Powodów może być kilka. Postaram się wymienić te najczęstsze.
- Blokowanie adresu dyrektywami uniemożliwiającymi skanowanie i indeksowanie zasobów przez roboty wyszukiwarek.
- Ustawienie adresu kanonicznego na inny URL.
- Google wybrało inny adres kanoniczny dla podanego URL.
- Wystąpił problem w trakcie pobierania strony przez robota (błąd 5xx, błąd 404) lub strona została przekierowana na inny adres.
- Robot odwiedził stronę i umieścił ją w kolejce do indeksowania.
Na zakończenie
Indeksowanie jest jednym z ważniejszych elementów, o który trzeba zadbać, prowadząc stronę firmową czy prywatnego bloga. Brak obecności witryny w indeksie Google sprawia, że potencjalny czytelnik będzie miał problemy ze znalezieniem naszej strony w Internecie. Jeżeli tylko masz wątpliwości czy adres URL został zaindeksowany koniecznie dodaj stronę do Google, korzystając przy tym z jednego z wymienionych przeze mnie sposobów.

Od 2018 roku związany jestem z marketingiem internetowym. Specjalizuję się w optymalizacji stron internetowych i sklepów. Obecnie pełnię funkcję Marketing Managera w Agencji KS. Prywatnie jestem miłośnikiem fantastyki oraz zapalonym czytelnikiem.